
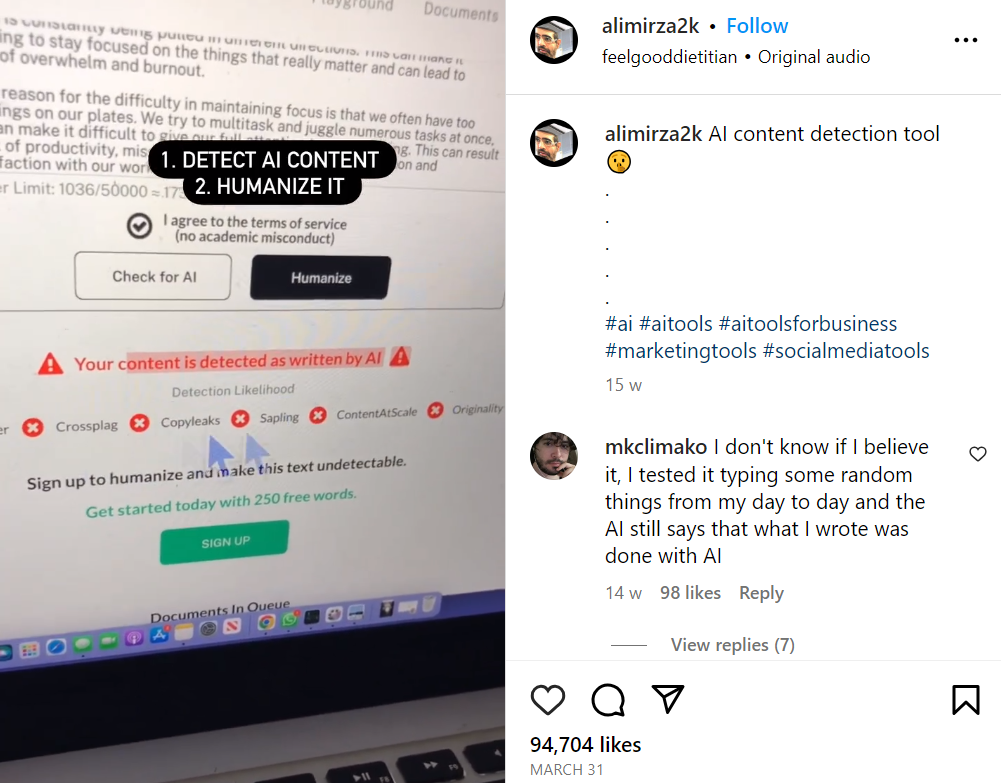
In today’s fast-paced digital world, AI models are becoming more powerful, but with that power comes a critical challenge: ensuring they are aligned with human values. From London’s bustling tech hubs to the global stage, AI alignment is a top priority for developers and businesses alike. This guide breaks down the core concepts behind shaping AI behavior, focusing on two key methodologies: Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF).
AI Alignment
A visual comparison of Supervised Fine-Tuning (SFT) and Reinforcement Learning (RLHF) in shaping AI behavior.
🎯 What is AI Alignment?
Alignment is the process of training AI models to act in accordance with human intent, values, and preferences. The goal is to create AI that is helpful, harmless, and honest.
Supervised Fine-Tuning (SFT)
SFT trains a model by showing it high-quality examples of correct answers, much like a teacher instructing a student to imitate them.
Alignment Granularity
Coarse
(Entire Answer)
Balance of Pros & Cons
Reinforcement Learning (RLHF)
RLHF refines a model by letting it generate answers and then rewarding it based on which answers humans prefer, like a coach providing feedback.
Alignment Granularity
Fine
(Specific Sentences)
Comparative Strengths
The Combined Power
In practice, SFT and RLHF are not mutually exclusive. They are most powerful when used together in a two-step process to create highly capable and aligned AI models.
Step 1: SFT
The model learns foundational knowledge and response style from a curated dataset.
Step 2: RLHF
The model’s behavior is fine-tuned to align more closely with nuanced human preferences.
Result
A more helpful, harmless, and reliable AI assistant.
At a Glance
| Feature | SFT | RLHF |
|---|---|---|
| Goal | Imitate correct examples | Maximize human preference score |
| Process | Learning from static data | Learning from interactive feedback |
| Best For | Teaching format & style | Refining nuance & safety |
What is AI Alignment?
At its core, AI alignment is the process of training AI models to act in accordance with human intent, values, and preferences. The ultimate goal is to create artificial intelligence that is consistently helpful, harmless, and honest. Without proper alignment, an AI model might generate unsafe or biased content, even if it has a vast amount of knowledge.
Supervised Fine-Tuning (SFT): The Foundational Step
Think of SFT as a teacher instructing a student. In this method, the model is trained on a curated dataset of high-quality examples. It learns by imitating the correct answers, absorbing the foundational knowledge and preferred style of response.
- Process: The model is fed a large dataset where human-written prompts are paired with ideal, human-approved answers. The model learns to replicate this behavior.
- Granularity: Coarse. The model learns to align its behavior across entire answers or conversations, focusing on overall style and format.
- Best For: Teaching the model a specific tone, style, and set of foundational facts.
Reinforcement Learning from Human Feedback (RLHF): Refining Nuance
If SFT is the teacher, RLHF is the coach. This method refines the model’s behavior by allowing it to generate its own answers and then rewarding it based on which responses humans prefer. It’s an interactive, feedback-driven process.
- Process: A human ranks different AI-generated responses from best to worst. This feedback is used to train a separate “reward model,” which then guides the main AI model to generate answers that maximize its reward score.
- Granularity: Fine. RLHF can refine the model’s behavior at a much finer level, focusing on specific sentences, word choices, or nuanced safety considerations.
- Best For: Honing safety, creativity, and subtle adherence to complex human preferences.
The Combined Power: A Two-Step Process
In practice, SFT and RLHF are not used in isolation. Their true power is unlocked when they are combined in a two-step process to create highly capable and aligned AI models.
- Step 1: Supervised Fine-Tuning (SFT)
- The model learns foundational knowledge and a basic response style from a curated, high-quality dataset. This gives it a solid base to work from.
- Step 2: Reinforcement Learning from Human Feedback (RLHF)
- The model’s behavior is then fine-tuned using RLHF. This allows it to adapt to nuanced human preferences and safety guidelines that were not captured in the static SFT dataset.
Result: The final product is a more helpful, honest, and reliable AI assistant that can be deployed with greater confidence in a variety of applications.
At a Glance: SFT vs. RLHF
| Feature | SFT | RLHF |
| Goal | Imitate correct examples | Maximize human preference score |
| Process | Learning from static data | Learning from interactive feedback |
| Best For | Teaching format & style | Refining nuance & safety |
Export to Sheets
As the global AI industry continues to grow, particularly in innovation hubs like London and Cambridge, the importance of robust alignment techniques cannot be overstated. By understanding the roles of SFT and RLHF, we can appreciate the sophisticated processes that ensure AI systems are not only intelligent but also safe and beneficial for humanity.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
+ There are no comments
Add yours